
From its early beginnings as network management via SNMP traps, Operations Manager expanded into application management, pivoted from a host- to a service-centric CMDB-based model, implemented on a new technology stack, then gained the ability to integrate with numerous third-party sources of event and metric data, in addition to its own collection, which works both with agents and through remote probes. As the Operations Bridge, it offers a consolidated view of heterogeneous, hybrid environments, with a unified view on events and health information that pinpoints root causes and affected services. Far from being a simple event browser and trigger of remedial actions, it can generate trouble tickets, send email alerts, execute automated runbooks, and show detailed reports and dashboards. A new data ingestion does away with multiple data collection and storage, and analytics with machine learning algorithms promises data analysis that doesn't require tedious configuration.
The Operations Bridge Suite ships as a cloud application, which means that you provision one or three master nodes, and any number of worker nodes (that can later be scaled up or down), either as physical (Linux) systems, or virtual machines in a private or also public cloud (like Amazon AWS instances). An installer that is common to all Suites bootstraps a Kubernetes environment, and lets you select the desired Suite capabilities, each of which consists of a set of Docker containers that can then be sized according to your needs. In contrast to a classic deployment, this offers more flexibility, built-in high availability, and integrations among capabilities that work out of the box.
HPE Operations Bridge Development Engineer
Feb 2016 - Sep 2021
Put OMi into a Docker container for a hyperconverged appliance, then productized this as part of the first private cloud-based monitoring solution for Hybrid IT.
 |
Out of nowhere (to be exact outside of the software group), a daring project suddenly showed up, kind of skunkworks (as far as a big bureaucratic company is able to do that), with a bold name, fuzzy details, and lots of management attention: The hardware guys wanted to take some of their (very successful) blade servers, put a selection of our own software on it (some existing, some newly written, all running in containers), and sell that as an appliance that customers just put into their data center, supply power and a network connection, and it'll be able to provision, run, and manage virtual machines (that last part being the responsibility of our software).
I became part of a team tasked with taking our existing Operations Manager i software, packaging that as a Docker container, and making it run inside that appliance. It quickly became clear that the hardware guys had little knowledge about how our existing products work (and the historical baggage that comes with them), mostly ignored architecture and recommendations, and had put up extreme resource requirements that sort of required multiple technical miracles (which our architect countered with galgenhumor and cynicism). Basically, their main contender in the market (Nutanix) was a small, focused application written by a startup just for that purpose. They wanted to quickly plug together a solution from existing software solutions (that were developed for different use cases, and as enterprise applications optimized for scalability and robustness, not small footprints) that could deliver the same functionality (and more), yet ship within an equivalent physical system. Early projections showed that the box would require most of its resources just to run itself — hardly any space left to run the customer's workload!
An intern had already successfully installed the Linux version of OMi inside a container, based on a CentOS image, and then running that on a CoreOS Docker host. I took over the Dockerfile and surrounding infrastructure scripts, and integrated that within our builds. In order to trim down the multi-gigabyte image, there were some steps we could do on our own (like reusing the JRE from the base image instead of bringing our own); other steps required the coordination with other component teams within the company (e.g. to obtain a separate uCMDB container). A big challenge here was that on the one hand we had to make big cuts and changes to meet our targets, but on the other hand we could not fork the code base (which was too large and complex to maintain two versions of in parallel), and also were forbidden to affect the classic installation of OMi, which during the project's time frame would have to do several releases.
I solved those challenges via feature toggles (for example, if a UCMDB_HOST environment variable was set, a remote container instance would be contacted instead of the embedded local one that shipped with the classic product), preprocessing (the installer got a hidden feature definition for the container installation that skipped several packages), and post-installation adaptations (XML configuration of configuration steps was rewired via XSLT transformations). With my long history with Linux (and Unix), I deftly applied my expertise about Linux tools and scripting to solve these tasks quickly and efficiently, without having to reinvent the wheel.
I invested a lot of effort in a clean build and development setup; as the Build Factory with their short-term, interrupt-driven work just copy-and-paste things around, I took it upon myself to factor out build steps into separate scripts, unify the component and system test setups (that were hundreds of largely identical lines of shell script), and create Docker compose setups for development (with debugging support) and testing (with additional components like an external Agent container). With this, we got timely test results, which were immensely helpful to catch any regressions, and we had versatile environments (e.g. I later added secure communications via private SSL certificates) that were much easier to troubleshoot than the complete appliance (which used Kubernetes for orchestration, and required a very powerful VMware ESX host to run). Other contributing teams from our organization reused some of our stuff, and I published a generic script I had implemented for externalizing persistent data for them.
In the end, despite a successful conclusion in May 2017, the appliance was never released to customers in that form. Though our team had met the aggressive targets for resource consumption (through a strip-down of our monolith and tricks like squashing Docker layers into one), we couldn't shake the feeling that poor project management (the worst I had ever experienced) and lack of architectural clarity may have contributed to the eventual insignificance of that event; like a Pyrrhic victory, a face-saving declaration of success. Symptomatic of the whole project, none of that was officially communicated to us, and our team was left in a month-long limbo as to whether there would be follow-up successor project or not. (We eventually did see a comeback of the bad project manager; she took a severance package in that company and then was soon re-hired by the now spun-off software division as an R&D-manager reporting directly to the VP; her connections must have paid off handsomely.) Politically, winds had changed, too, as it was decided that the software part of the company will be sold off (killing the arguments of internal leveraging and upsell opportunities, and instead requiring an official support deal between the two future companies). Presumably under a "plan B", the company also had acquired SimpliVity, which comes with similar functionality, and probably will merge with whatever remains of the HCOE project.
Fortunately, most of that turmoil didn't affect our software organization, and we basically got a head start with container technologies paid for by the rest of the (soon to be ex-) company! The non-invasive changes done by our team to run OMi in a container environment were either reused or served as the basis for a new implementation when shortly thereafter ITOM management decided to offer containerized application suites as the delivery vehicle for future developments (while keeping the current classic point products for many years in parallel). Ideally, our group (which the common adversary and steady stream of WTF-moments had gelled into a well-functioning, tightly-knit Agile team) would have picked up that task. Unfortunately, we were at the time still committed to the project, so a neighboring team picked this up, mostly didn't talk to us, and so unnecessarily reinvented many wheels and did things in a different way "just because". History repeated itself one more time.
 |
Together with the new strategy of containerized suites, the R&D teams adopted the Scaled Agile Framework for Lean Enterprises, with trainings and certifications, a whole basket of new roles and terms (and unfortunately also kept around the same managers who previously already had attempted an Agile transformation and showed that they were mostly still stuck in their old mindsets). We started our first Program Increment in September 2016 with a two-day planning workshop. Though we deviated from the theory in crucial areas from the start (no co-location, still separate QA roles, no integration of non-R&D groups), it felt like a positive change, and had the potential to give much more power to the individual teams, and with that a chance to finally tackle the crippling technical debt, siloed development, and lack of knowledge sharing.
My team both had a head start (as an already formed team) as well as a big disadvantage in the form of our ongoing commitment to the hyperconverged appliance. A merge with another Agile team in January 2017 brought us closer into the fray, but still partially committed to those side tasks. At the end of that month, the first OpsBridge Suite 2017.01 containing OMi version 10.60 was released.
In May 2017, we merged with yet another Agile team, the appliance tasks had been wound down, and a new main responsibility area had been identified for us. (The organization was still ambivalent about the "T-shaped developers", as mandated by SAFe, who could work on anything and had a few specialty expert areas each, and the historic siloed (= fixed) distribution of knowledge and responsibility, which together with a lack of documentation and time for pair programming made it difficult to move into that direction. As a result, bug fixes were mostly a free-for-all (with the jump in attrition many experts were gone, anyway), but feature development was assigned to particular teams.) Suites were based on a common framework that installs the basic Kubernetes environment, provides APIs for the management of a Suite and its customer-visible capabilities, and prescribes certain protocols in order to orchestrate administration tasks like authentication and backup of Suite data. I would have loved to work on that framework, as it requires the precise, forward-thinking, generic design I excel in (e.g. first in the ConfigFilePolicyType); sadly, this was given to an inexperienced offshore team in Shanghai with second-rate architects from Europe. Our organization was spearheading that integration (as we later learned other Suites were hedging their bets and much slower in picking up features from the framework, one even mostly ignored its functionality and implemented things on their own, which in retrospect would have been a prudent decision, but not politically viable for us).
Suite configuration is implemented by a set of web service endpoints in a set of Java Spring Boot applications, invoked by the framework during installation and reconfiguration of the Suite. There's a general part and capability-specific parts to that (though that didn't matter that much in the beginning, as we started out with just three capabilities). Our team took over the development of that; my first feature was the addition of more database options, both in a small HTML UI and the Java backend that integrated with multiple web services and Kubernetes. Though all of that code was fresh, in the mad dash to keep up with biweekly framework releases, maintainability and structure of the implementation had suffered, with a purely procedural implementation that used untyped dictionaries to store data (often redundantly), often just logged errors instead of returning them (so there was no appropriate UI response, and you had to inspect the log file to see what happened), and copy-and-pasted or alternative implementations of basic infrastructure code (for example, four different libraries were used for web service calls, and the main motive for choosing seemed to have been whatever the developer was familiar with or found on the Internet).
Together with the usual lack of documentation, and only dead or broken code for development support (no debugging in a real environment; conditional branches to run the code locally had been abandoned but inconsistently kept in the code base), it was difficult to get up to speed, but as this is rather common in our industry, and had repeated itself so many times in my career, I bit the bullet and familiarized myself with the code through a first wave of refactoring, both to learn about the code's function and to eliminate the worst duplication, to bring some structure and coherence to the code, and to allow an expansion of test coverage (which started out at around 13% and a year later was close to 50%). The number of classes had multiplied, yet the overall code size had been reduced. Many latent bugs were detected and fixed. Remaining issues have been documented as technical debt. The refactoring was ongoing in tandem with feature work. Unfortunately, the effort still was mostly a one-man effort, because the team hadn't picked up pair programming (we've been overloaded with features and instead of jointly working on a single theme in each sprint, each developer had his own unrelated feature (or even several in the worst case)), and knowledge about refactoring and Clean Code was limited (whereas I had read the Refactoring book and Clean Code trilogy long ago on my own initiative).
The frontend was developed by engineers with little UI knowledge, using mostly plain JavaScript with Bootstrap and jQuery libraries, and just a bit of AngularJS (our main UI framework) thrown in. Source code was statically packaged without a build, and libraries checked-in alongside the code. All code was put into two files, and additionally interacted with framework code injected into the page. No design to speak of, and no testing or development sandbox made each fix (no matter how small) a big challenge. I've successfully made several enhancements and identified and fixed problems introduced by predecessors; others (even dedicated UI developers) also made changes and unfortunately introduced regressions — something I could avoid through my diligence, and by working in very small steps. I motivated the creation of a simple dev harness, and pushed for having the frontend designated as legacy code. Stakeholders agreed that no changes except small critical fixes will be done, and a feature to rewrite it had been placed in the backlog (where it remained indefinitely).
Throughout quarterly Suite releases, our team implemented complex upgrades (through another dedicated upgrade container), enabled the possibility to apply patches to container images, backup and restore of Suite data, and non-interactive installation by supplying a JSON configuration. All of those features were made more difficult by haphazard decisions of the framework team, and low quality of their deliverables:
 |
In order to obtain clarifications and fixes, a change request had to be submitted, and often these would be closed without further comments, or asking us to open an enhancement instead (instead of simply toggling the type on their side on the existing CR). Our organization's setup of different ALM instances then further complicated our appeals. Our Product Owner often implemented requested changes himself to increase the chance of getting them accepted. Proper change tracking (simple things like what got fixed when and delivered with which version) required several complaints through our management (though a common detailed template for the resolution is pre-filled, all they often entered was the word fixed
). When I once looked into one of their fixes, I found poorly obfuscated scripts, checked-in build artifacts, development done in private developer repositories, and even software of questionable origin! When I reported this, I got oh, this should have been corrected a long time ago, the responsible developer has left the company
from the architect, and no response from the manager I reported the breach of company rules to. As I'm very keen on following, understanding and continuously improving company processes (these things, if done well, are what set us apart from our competitors), this was very frustrating.
It wasn't just the problems with the framework or our own poor procedural implementation that made progress so slow. After the two mergers of Agile teams, we slowly lost people: The architect for the hyperconverged appliance emigrated to different job and country shortly before the project wound down, our first Product Owner left for another role, and then the company. Our Scrum master switched teams (so developers without formal training reluctantly picked up the role), then two developers moved with the Monitoring Automation component to another Agile team, finally even into a different release train. At four developers (two senior, two junior) plus one engineer with QA focus, we were stretched really thin. The Agile process was streamlined, unfortunately in a way that emphasized management visibility (forcing us to update mostly meaningless user stories with daily progress) and disenfranchised the team. Retrospectives were first cut short (like in the past Agile attempt, there was no follow-through on the hard problems), and then abandoned altogether.
Planning, which should be done democratically by the team, with estimations based on past velocity, were done in private by the Product Owner, architects, and managers. One of the few positive things was the introduction of an Innovation and Planning Iteration, but that was quickly misused to catch up on open ends and "finalize" user stories. In the quest to deliver features, the organization often let cumbrous homework and cleanup fall under the table, and continually overloaded the system. Each Product Increment started with teams almost fully booked (according to often optimistic estimates done without regards to historical data, by a small group that did not include the developers), and then regularly added 25% during the course of the increment. Our Release Train Engineer just reported these problems, admonished the teams, and then continued as if nothing happened, only to repeat the same two weeks later.
Soon, management was forced to cut some corners, and the proclaimed rule of quarterly releases was weakened, so that we would skip either classic releases, and just ship a (minimally) updated OMi container, or instead skip a Suite release.
Productivity was impacted much worse by the third-level product support work that we had to shoulder since January 2018. This was a result of management first communicating that support work had no future locally, which caused a majority of the (mostly veteran) engineers to take another good look at the voluntary severance program that was offered at the time, and take that package. All of a sudden, we had no support team, and the offshore replacement was still in the hiring and build-up phase. So it was announced that local teams had to temporarily pick up support cases until the offshore guys were in place and up to speed. With that, despite being thrown in at the deep end, and having to deal with functionality I had no immediate experience with, I tried my best to solve the cases assigned to me, in rotations of four weeks; my long history with the organization and broad troubleshooting knowledge helped with that. In a way, all the good work I had done in the past now backfired on me, as there were few to no cases in those areas (like Content Manager), and instead most of the problems were in those tar pits I had so far successfully avoided.
Now all of that would have been endurable for a limited amount of time, but soon management reneged on the temporary nature, and instead said that support work is here to stay
. With the decreasing number of people in our team, that meant regularly doing four weeks of support work after six to eight weeks of development. It was hard to plan or complete features in those time frames, and the constant shifting in and out of roles had a huge toll on productivity and engagement.
In late autumn 2018, our team was informed that all containerized Suite-related activities (both R&D and QA) would be transitioned to a new team in India. With six capabilities, the huge coordination effort had severely cannibalized our core mission of working on OMi; this no longer was a small side job. Management wanted to execute this very quickly, and ignored our objection that this is the worst possible time, as we were both in the middle of a large refactoring (that showed really promising results) and an API shift of the underlying foundation (that dragged along much slower than expected), and keeping this responsibility for 6 to 15 months made much more sense technically. In the end, this was a pure political decision, based on the available people (who came from the other half of the merged company and whose product was discontinued as part of the merge). Neither their technical background nor their composition (initially just one core developer, with another one freshly joining, but still occupied 30% with previous assignments) fit the purpose, and this, together with problems in obtaining the considerable computing resources required for dev and QA (they weren't allowed to clone our proven local setup and instead had to go with a new central IT offering that wasn't yet fit for purpose) then inevitably lead to execution delays.
So the program increment that was planned for transition saw almost no inquiries from their side - our team led several recorded sessions, but then never heard back from them; first software licenses were missing, then computing resources, and so on. Only one increment (3 months) later did the actual transition start in earnest, with almost daily pull request reviews and spontaneous conference calls, in which we discussed technical directions. This delay also affected our team's future responsibilities - that decision could have been made before Christmas already; I first waited for news after the winter holidays, then around Easter, finally management made that decision in June (apparently it took them so long because there were so many conflicting wishes and desires from product management that they couldn't decide on a direction sooner), but didn't tell us until mid-July (to avoid distracting us from our ongoing transition, according to my boss). When they finally revealed it (in an impersonal email), it was a huge disappointment: Instead of a comprehensive assessment of future investment areas (that addressed the huge frustrations in the two remaining Agile teams that remained for development on OMi in Böblingen) and re-balancing for sustainable development (preventing the arbitrary support case assignments and constant shifting of feature work), the new plan looked like it was drawn up in five minutes, with the other team completely unaffected, our team getting the two most pressing (and unattractive) legacy components, and a formidable list of white spaces (that could keep another full team busy) remaining undecided (read: escalations from those would continue to spill into our teams). To top this off, the whole eagerly awaited decision became obsolete within a week, as another manager (a major stakeholder in that reassignment) cannibalized our team by offering a limited rotation into UI development (that was likewise suffering from severe resource shortages, and unable to accomplish the committed replacement of legacy technologies in time), and one of us took the bait. And that's how it mostly just fell apart.
At the end of 2019, the transition had been done; a switch to a (still unproven (bad) third-party (good)) technology may mean that the new team won't have to do substantial changes to the inherited code (which may explain why refactorings I'd submitted to them were ignored for two PIs in a row, and still linger on), but rather can (re-)implement features with that new technology. Despite the bad conditions, our team managed to execute the handover smoothly, getting praise for our professionalism and deep expert knowledge. To prepare for the transition, I had designed the required repository split (the code had been in the wrong repo since the beginning, due to heavy red tape), executed the cloning and set-up of completely new builds in a dedicated CI-Farm (running on Jenkins), and originated an organization-wide shared library of Jenkins task definitions, to try to stem the usual rank growth of build scripts — successfully, as key engineers picked this up for other projects soon. A related repo-split project for the automated tests didn't fare so well — although it basically just had to follow in our paths, it six months later still wasn't completed. In fact, a whole year later one developer (who is associated with our team, but basically does QA-related work on his own) was still busy adapting test cases to the improved API.
Another stroke of good fortune came by management finally accepting the ongoing complaints about the third-level support work; our head of department followed recommendations presented by me as part of an improvement committee and reinstated a dedicated support team. However, teams here were still falling apart, and it looked like at least local work on OMi would slowly wind down; a first team had started work on future micro services. Due to the loss of those resources, and further attrition, my team merged with its only remaining sister team.
 |
Most of 2020, our team spent implementing and extending JSON-based REST web services, as our still mostly Flex-based UIs had to be rewritten as web UIs until the end of the year (when Adobe finally pulled the plug on the abomination that is was Flash Player). We had to pay the price for the chaotic historical hodgepodge in the backend; some services just required a more or less straightforward extension of the existing JAX-RS model (with the main challenge being the lack of documentation, test coverage, and no people with knowledge remaining in the company), some needed to be rewritten from scratch, and a few were deemed so complex and brittle (including the Content Manager that I had previously extended and made more robust) that the existing XML output had to be transformed to JSON. Anything but exciting, those mostly mechanical translations required just a bit of diligence and considerably more lip-biting when confronted with the poor design of the code and automated tests. We had gotten the weak promise that after this episode of dull maintenance, our assignments would be shifted to work on new micro service implementations for the next generation of our product. But the fact that so far only one small 3-developer team had started in that area, and in the meantime had to interrupt that work to adapt our OMi container to the now Helm-based Suite installation, didn't bode well for the future.
It wasn't just me who worried about our atrophying design and technology skills: we lost two more veteran team members over the course of the year, while hiring happened only elsewhere and even there did not fully replace all resources that had left (and those replacements were all entry-level). Our team consisted of four developers, two QA engineers, Product Owner and Scrum Master / Project Manager, and two rogue developers who were associated with our team, but actually worked on completely separate stuff. One positive side effect of the boring nature of our work was that it allowed us to easily adapt to the phase of home office that started during the Corona virus lock-down in March: The web service conversions could be done by individual developers and required no collaboration; each of us had ample general knowledge but knew no details about the functionality; each sprint, some would work on those features and the rest would handle incoming defects.
So we steadily delivered one web service after the other; the pressure definitely was on the UI teams who had to tackle the huge task of re-implementing all Flex UIs, a task which once more had been hugely underestimated by management and was started way too late despite the hard deadline. It subsequently exhibited the whole cornucopia of corporate mismanagement: the mentioned poaching of developers from other teams, then short-term hiring of contractors (which the Indian part of the organization even didn't manage to do due to the huge competition there), extension of command-line interfaces as a fallback should the UI not be ready, and finally preparing external documentation of the internal data formats so that customers could edit those in raw form.
The permanent overload of the UI teams caused backend changes to be picked up only several Sprints later (or even months later in the next PI), so first there was no feedback at all (we followed a "lightweight" documentation approach through sketching the requests and responses in a Wiki page; that was our anti-Agile "throwing over the wall") and then suddenly pressing urgent defects that prevented the UI team from accomplishing their feature. All those unrealistic schedules prevented us from making any significant steps toward an effective agile setup: No more UI / backend segregation, refactoring of the architecture towards componentization and consistency.
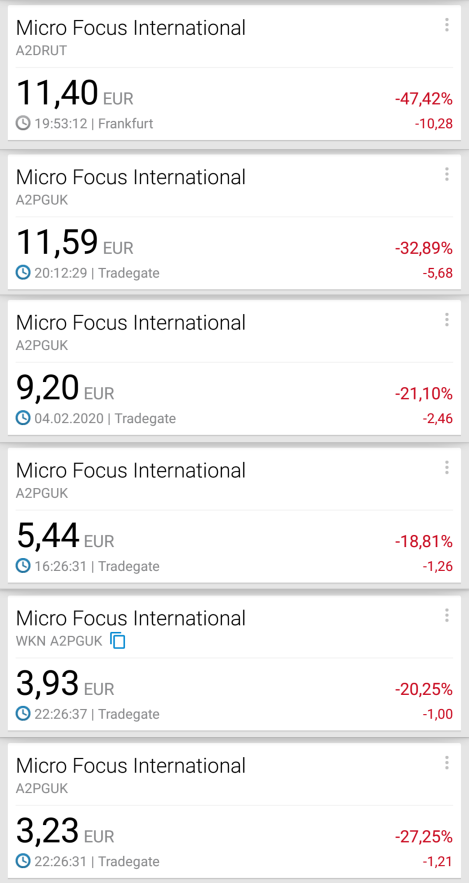
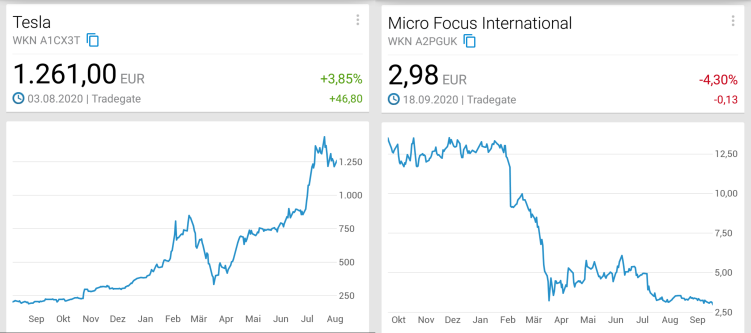
I did implement a Jenkins-based CI build that is triggered by pull requests, but only for one of our large legacy repositories; the inclusion of the second big one could have been a matter of simple copy-and-paste if only we had done just minor steps towards consistency. Sigh. The third main repository is now owned by an offshore team; management was very keen on us doing a training session, but nothing came of that. I think that they are lacking the senior developers that understand the value of leveraging such efforts; the mostly junior developers there are even more trapped in the wild dash of feature development, lacking the clout and long-term perspective. The problem is that these sites and behaviors are expanding, whereas we're steadily losing those veterans that so far have upheld our competitive edge. Whatever change there is is too little, too late. Three years have passed since the big company merger, yet the company is still mostly split into two separate tech stacks, a notebook replacement process has been reinstated only now (so I'm still using one with a broken battery that's been in use for eight years now — that's also severely limiting my options for working from home); IT support is unhelpful, and basic processes (like updating the internal address book) are broken. No wonder that since its all-time high, the share price has taken double-digit dives — not once or twice, but a full five times, and the company is valued at less than a tenth. So sad.
 |
In early 2021, most of the Flex UIs had been removed (our team had temporarily hosted the last few contractors involved in this, before these were transferred to an Indian team — no, none of this made any sense, and just wasted everybody's time in the daily standups, but it made things a bit easier for the Scrum master and PO), though for the time being the implementation was still kept in the source code (and only planned to be removed after the November release - apparently we didn't have that much trust in our replacement UIs nor in the revision control system). In one of our most frustrating PI plannings, we weren't allowed to throw out stuff that was definitely under the cutline, and priorities were still shifting as we were planning (marketing, Suite leadership, and R&D apparently could not decide early on, and instead made everyone suffer). And that happened just two weeks after some Agile steering committee presented the latest Agile survey results, with teams being overloaded again reported as the top issue. Just a day before planning, our team was merged (temporarily, or maybe permanently — no one could tell) with the two people from the team that should have worked on the future micro services, but effectively had spent the majority of their time on the legacy containerization of OMi, and that task was now brought into our team, as there were more things to do, especially with enabling deployment to public clouds (which, with the right architecture, we could have gotten for free). So, our team would continue to be heavily fragmented, just replacing the recent UI focus with more container work, and none of that on real innovation, but trying to adapt our bad existing design to customer requirements, with the investment into the future architecture postponed for the time being.
So what we did work on were catch-up actions, mostly the support for installation in Cloud environments (Amazon's AWS and Microsoft's Azure), which in my opinion suffered from the lack of internal vision: Starting with our container framework (CDF), which did not provide the necessary abstractions, which then was alleviated by poorly-maintained (and often read-only; a horror for a deeply collaborative guy like me) Wiki pages (official documentation was notoriously late and sketchy, having been derived from just these Wiki pages) and multiple toolkits (our own managers were also confused by these, even mixed them up, and assumed just one would do, understaffed one with a focus on internal QA, but promised everything would just work — well, it surely didn't for the first release (and nobody updated the Wiki pages for the second release)). We (in parallel with other teams, in a great waste of time — at least we were able to collaborate and help each other through a dedicated Teams channel) struggled mightily to do the first setups with these poor instructions. I learned a lot about these new and interesting cloud technologies, so it wasn't all bad. Driven by the frequent reinstallations of the cloud environments (managers did check that these were all shut down at least over the weekend to save costs — it felt like that little cost report bit of this frightening new technology was the only thing they could understand, and they embraced that with vigor), I rewrote my setup scripts for my personal home directory, leveraging a tool I'd written to automate and record the software installation and customization of my new dev notebook. I also diligently documented the installation steps and configuration data, which greatly sped up the testing for the following release, and will help my successors.
 |
Naturally, the frustration within the team (all long-time employees who've already shouldered a lot) was visibly growing, and I think this is what finally pushed me over the edge, and into leaving. By falling behind in the rejuvenation and upkeep of our software, we got caught up more and more in maintenance and workarounds, until it's too late. Young and nimble competitors surely were already working on solutions in the Operations Bridge space, unencumbered by our calcified management structure and legacy software. In the end, our management will need to acquire one of these companies and then quickly shoehorn their product into our solution, and we lost our chance at coming up with a good solution on our own, and providing a smooth transition for our customers. I've seen it all play out like this two decades ago, when our vision of a common component-based software architecture for all OpenView products fell apart and was followed by a series of buyouts of smaller companies, which we then spent years integrating. On the organizational side, we were still trying to hire full-stack developers into teams that are solidly segregated into frontend and backend (which, together with our company's bad name recognition and poor salary offers should explain why we attracted few qualified people). Even though our team was widely regarded as doing a superb job and having the best track record in terms of defects and deliveries, we didn't even get a promise of getting the next hired developer from our management. Instead, (in a reluctantly held session on last year's employee feedback (taken three months earlier (!) — the company is very keen on collecting, but not so much on acting on such feedback)) my boss tried to sell the take-up of undesirable side jobs (the example was being the team's I18N coordinator) as progressing on the career path, acknowledged that it will take on average about fourteen years for an individual promotion in our (excelling — remember?) team, and fell back to tropes like beware that it just looks like the grass is greener on the other side
when our scrum master mentioned more positive developments of her husband's closely related job in a very similar nearby company. I can be really thick when it comes to organizational politics — but that one even to me sounded like it screamed go get another job
all between the lines!
Though being a great buddy fine human being, my last boss has been the most useless (and clueless) I've ever had! Destiny had it that it's the same person who was my first mentor on my first job; he then soon switched to management and in 20 years didn't make it beyond first-level manager. Never been technically strong, and with the switch to Agile practices much less involved in the day-to-day development tasks, he was mainly occupied with organizational busywork (like influencing the future hardware strategy for a year and then not getting what we'd wanted), attended some meetings where his only real contribution is a bit of pep talk (keep up the good work, team
) at the end. I got so tired of his way of deflecting my feedback (I cannot disagree with you here
- but then doing nothing) and criticism (the grass is always greener on the other side
- that's hard to argue against, but most employees also agree that it has been better here, in the very same company, just a couple of years ago). His idea of management apparently was sending around monthly links to trainings that might be interesting to you without providing any objectives for your development (he couldn't, as the organization itself didn't have a plan about the future). Like many other managers around him, he had no real understanding of the tasks at hand, so there's only stupid questions and impractical suggestions (that often deal with saving money). Instead of advocating excellent communication and collaboration, he spent a good amount of time just forwarding various emails. After years (if not decades) of decline, the company ranks are devoid of motivated and skilled people; while the remaining employees have made amends with the situation, and try to go along with the least amount of friction. Trying to change the company is futile, as the management is too entrenched and the organization too big and slow to change. My stubborn self finally had to accept this, and I then knew that it was time to move on.
It's really sad to see this once great engineering company with a unique and world-renowned culture (the HP way) had become an MBA-driven business focused on (mostly elusive and short-term) financial success; the more it neglected its great roots and heritage, the more it started to struggle. Sadly, this destiny has become all too common; for example the committee report on Boeing's 737 MAX development drew eerie parallels where a cultural change started by a merger led the company down a path of denying its quality focus, falling behind competitors, and then increasingly using short-term fixes and questionable practices to maintain its competitive edge.
Ingo Karkat; last update 05-Aug-2024